Classification
Project Date : 17 Januari 2022

Project Name:
Education: Student Performance (Project I: Magang dan Studi Independen Bersertifikat Kampus Merdeka)
Technology Project:
Python dan
Google Colaboratory
| No | Gender | Race/Ethnicity | Parental Level Education | Lunch | Test Preparation Course | Math Score | Reading Score | Writing Score | Keterangan | 1 | Male | Group A | Some High School | Standard | Completed | 70 | 99 | 99 | Unsatisfactory |
|---|
DESKRIPSI
Bagaimana memahami kinerja siswa(nilai ujian) yang dipengaruhi oleh variabel lain (Jenis Kelamin, Suku/Ras, Tingkat Pendidikan Orang Tua, Makan Siang, dan Kursus persiapan ujian). Adapun nilai-nilai ujian yang diprediksi dapat dipengaruhi oleh variabel lain meliputi Nilai Matematika, Nilai Membaca, dan Nilai Menulis. Kemudian Membuat beberapa model machine learning untuk memprediksi nilai siswa.
PROSES
- Pengumpulan Data Langkah pertama dalam pembuatan machine learning yaitu mengumpulkan data. Semakin banyak dan semakin baik kualitas data yang kita punya, performa machine learning yang kita buat akan semakin baik. Ada beberapa metode dalam mengumpulkan data seperti web scrapping, data mining, atau dari situs website yang sudah di sediakan seperti kaggle.com, data.go.id dan lain sebagainya. Adapun data yang digunakan dalam project MSIB ialah melalui situs kaggle.
- Exploratory Data Analysis (EDA) EDA atau dikenal pula dengan analisis data eksploratif merupakan pendekatan analisis untuk suatu data guna membuat gambaran keseluruhan (summary) data sehingga mudah untuk dipahami. EDA memungkinkan analisis memahami isi data yang digunakan, mulai dari distribusi, frekuensi, korelasi dan lainnya.
- Data Preprocessing Data preprocessing adalah teknik awal data mining untuk mengubah raw data(data mentah) menjadi format dan informasi yang lebih efisien dan bermanfaat. Format pada raw data yang diambil dari berbagai macam sumber seringkali mengalami error, missing value, dan tidak konsisten. Sehingga, perlu dilakukan pembenahan format agar hasil data mining tepat dan akurat.
- Feature Engineering adalah bagaimana kita menggunakan pengetahuan kita dalam memilih features atau membuat features baru agar model machine learning dapat bekerja lebih akurat dalam memecahkan masalah. Pada kasus project ini penulis menambah kolom seperti total score, average score, dan yang terakhir adalah keterangan yang berdasarkan average score yang akan menentukan lulus atau tidaknya.
- Label Encoder digunakan untuk mengonversi data kategorikal, atau data teks, menjadi angka, yang dapat lebih dipahami oleh model.
- Train-Test Split adalah membagi dataset menjadi train set dan test set, atau dengan kata lain, data yang digunakan untuk proses training dan testing merupakan kumpulan data yang berbeda. Dalam membagi test size pada umumnya sebesar 20% - 30%. Feature Scaling adalah suatu cara untuk membuat numerical data pada dataset memiliki rentang nilai (scale) yang sama.
- Evaluation Adapun algoritma yang diterapkan ialah KNearest Neighbors (KNN) adalah algoritma yang berfungsi untuk melakukan klasifikasi suatu data berdasarkan data pembelajaran (train data sets), yang diambil dari k tetangga terdekatnya (nearest neighbors). Dengan k merupakan banyaknya tetangga terdekat. Lalu yang kedua adalah algoritma Support Vector Machine (SVM) digunakan untuk mencari hyperplane terbaik dengan memaksimalkan jarak antar kelas. Dan yang terakhir adalah algoritma Multilayer Perceptron (MLP) adalah salah satu permodelan dalam teknologi jaringan saraf tiruan (JST) dengan karakteristik memiliki nilai bobot yang lebih baik dari pada pemodelan yang lain, sehingga menghasilkan klasifikasi yang lebih akurat. Maka hasilnya dapat dilihat pada tabel dibawah ini:
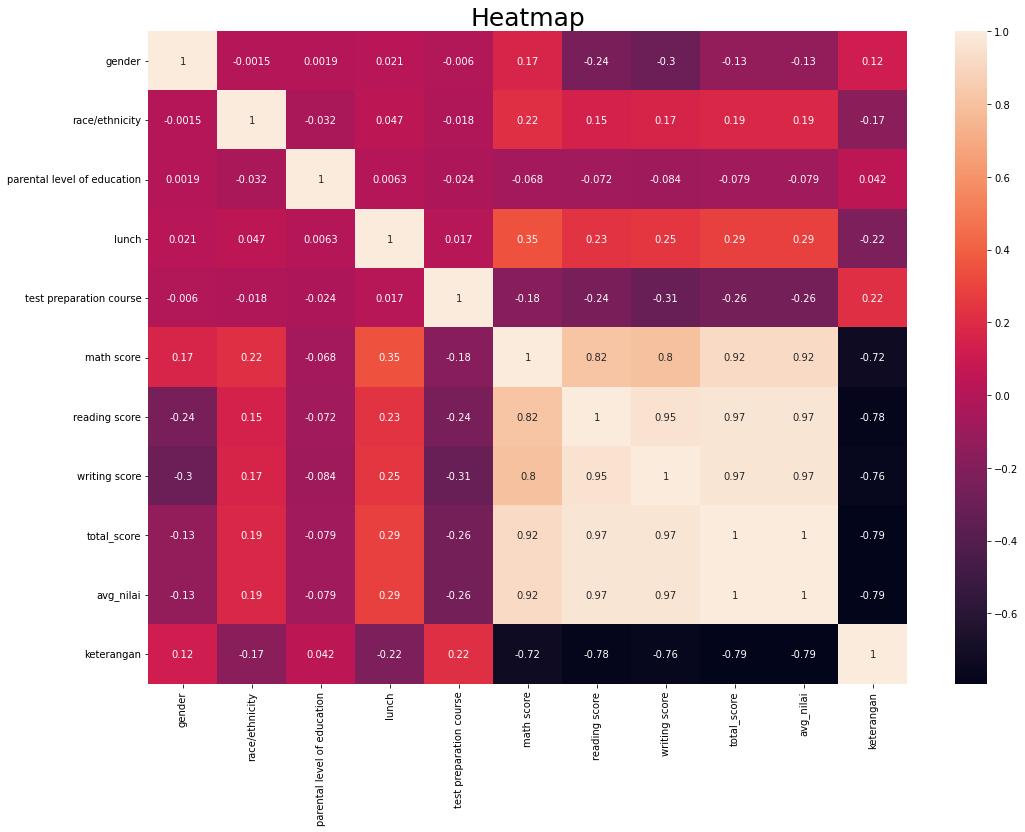
- SIMPULAN Berdasarkan hasil penerapan pemodelan machine learning yang sudah penulis lakukan maka merekomendasikan model Support Vektor Machine (SVM) untuk diterapkan dalam memprediksi data baru. Model performa training dan testing SVM merupakan good fitting dibandingkan algoritma KNN dan MLP. Kemudian berdasarkan heatmap dibawah ini, maka (lunch & math score) dan (test preparation course & writing score) memiliki korelasi lemah positif dan lemah negatif.
| Train-Test Split | KNN | SVM | MLP |
|---|---|---|---|
| Training | Accuracy : 97.38 % Precision : 97.43 % Recall : 97.66 % |
Accuracy : 98.62 % Precision : 97.71 % Recall : 99.77 % |
Accuracy : 99.88 % Precision : 99.77 % Recall : 100.0 % |
| Testing | Accuracy : 92 % Precision : 92.66 % Recall : 92.66 % |
Accuracy : 98.0 % Precision : 98.17 % Recall : 98.17 % |
Accuracy : 99.5 % Precision : 100.0 % Recall : 99.08 % |
Laporan MSIB