Analisis Sentimen
14 November 2023 • by Fordinand Pasaribu
INTRODUCTION
Analisis sentimen adalah proses menganalisis teks untuk menentukan sentimen atau emosi yang diungkapkan oleh penulis. Analisis sentimen adalah teknik dalam pemrosesan bahasa alami (Natural Language Processing/NLP) yang digunakan untuk mengidentifikasi dan mengkategorikan opini yang diekspresikan dalam suatu teks, terutama untuk menentukan apakah sikap penulis terhadap topik tertentu bersifat positif, negatif, atau netral. Ini sering digunakan untuk mengukur perasaan atau opini terhadap subjek tertentu, seperti produk, layanan, atau peristiwa, melalui analisis teks dari media sosial, ulasan produk, artikel berita, atau sumber teks lainnya. Berikut adalah penjelasan lengkap mengenai analisis sentimen:
- Tujuan
- Memahami Kepuasan Pelanggan: Mengetahui bagaimana perasaan pengguna terhadap aplikasi dan layanannya.
- Mengidentifikasi Masalah: Menemukan masalah atau kekurangan yang dihadapi pengguna.
- Meningkatkan Layanan: Memberikan wawasan kepada pengembang aplikasi untuk meningkatkan fitur dan kinerja aplikasi.
- Komponen Utama
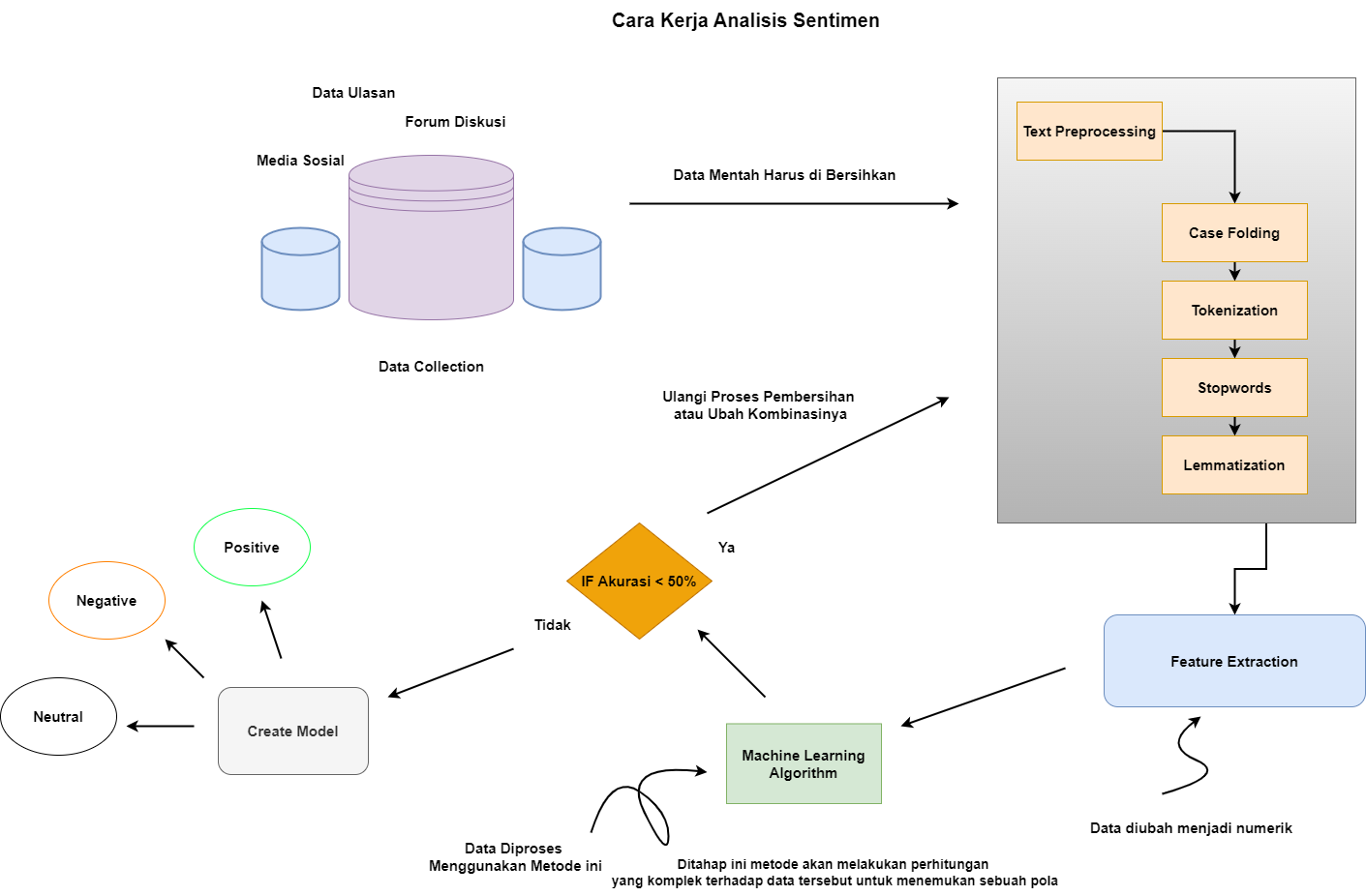
- Pengumpulan Data: Mengumpulkan ulasan dari toko aplikasi (seperti Google Play Store dan Apple App Store), media sosial, forum diskusi, dan platform lain di mana pengguna membahas topik tertentu.
- Pra-pemrosesan Data: Mengolah teks mentah untuk menghilangkan noise seperti tanda baca, kata-kata umum (stop words), dan melakukan tokenisasi.
- Ekstraksi Fitur: Mengidentifikasi kata-kata dan frasa penting yang menunjukkan sentimen.
- Klasifikasi Sentimen: Menggunakan model pembelajaran mesin atau kamus sentimen untuk menentukan apakah teks bersifat positif, negatif, atau netral.
- Metodologi
- Pendekatan Berbasis Kamus: Menggunakan daftar kata dan frasa yang telah diberi label sentimen untuk menganalisis teks.
- Pendekatan Berbasis Pembelajaran Mesin: Melatih model pada dataset berlabel untuk memprediksi sentimen teks baru.
- Pendekatan Hibrida: Menggabungkan kedua pendekatan di atas untuk hasil yang lebih akurat.
- Proses Analisis Sentimen
- Pengumpulan Data: Menggunakan API atau scraping untuk mengumpulkan ulasan dan komentar dari berbagai platform.
- Pra-pemrosesan Data: Membersihkan teks, termasuk normalisasi, tokenisasi, dan penghapusan kata-kata yang tidak penting.
- Klasifikasi Sentimen: Menggunakan algoritma seperti Decision Tree, Naive Bayes, SVM, atau model berbasis neural network untuk mengklasifikasikan sentimen.
- Evaluasi dan Validasi: Mengukur akurasi model dengan menggunakan metrik seperti akurasi, presisi, recall, dan F1-score.
- Aplikasi
- Pemasaran: Mengukur persepsi konsumen terhadap merek atau produk.
- Pelanggan: Menganalisis umpan balik pelanggan untuk meningkatkan layanan.
- Analisis Media Sosial: Memantau dan mengukur sentimen publik terhadap peristiwa atau isu terkini.
- Politik: Menganalisis opini publik terhadap kebijakan atau kandidat politik.
- Tantangan
- Sarkasme dan Ironi: Kesulitan dalam mendeteksi sentimen sebenarnya ketika pengguna menggunakan sarkasme atau ironi.
- Bahasa yang Beragam: Variasi dalam bahasa dan dialek yang digunakan oleh pengguna.
- Konteks: Memahami konteks yang lebih luas dari teks untuk interpretasi yang lebih akurat.
IMPLEMENTATION
Perlu mendapatkan API keys dari Twitter Developer:
- Buat akun di Twitter Developer.
- Buat sebuah aplikasi Twitter untuk mendapatkan Consumer Key dan Consumer Secret.
- Dapatkan Access Token dan Access Token Secret.
Python
# Scraping data menggunakan API Twitter
import tweepy as tw
import pandas as pd
# Menggunakan token dari twitter
consumer_key = '2kAfWmPvy5nPcoTOoRoIqSaIM'
consumer_secret = 'hkA4WAIWqS59s30QfMrj0EKJzHVf2bjBdif1HZM5DE6iUkaSX7'
access_token = '1539625531591004163-IuSh4LkDgd9wXmyaPvuosVBKUslKv5'
access_token_secret = '96bkZCGovhBLmLSVlu48Nlsj5xSp7rSQtvMwRggcopxLf'
auth = tw.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tw.API(auth, wait_on_rate_limit=True)
# Menentukan query
search_words = "aplikasi pln mobile"
new_search = search_words + " -filter:retweets"
# Mendapatkan data tweet
tweets = tw.Cursor(api.search, q=new_search, count=10000, include_entities=True).items(10000)
# Membuat dataframe dari hasil pencarian
users_locs = [[tweet.created_at, tweet.text] for tweet in tweets]
tweet_text = pd.DataFrame(data=users_locs, columns=["Tanggal", "Teks"])
# Menyimpan dataframe ke dalam file CSV
tweet_text.to_csv('plnmobile.csv', index=False)
Salah satu pustaka Python yang paling populer untuk bekerja dengan Twitter API adalah 'tweepy'. Instal tweepy menggunakan pip: "pip install tweepy". Gunakan Consumer Key dan Consumer Secret untuk mengautentikasi aplikasi dengan Twitter API dengan menggunakan metode api untuk mengambil data dari Twitter. Dapat dilihat pada codingan di atas.
Text Preprocessing
- Case folding adalah proses mengubah semua huruf dalam teks menjadi huruf kecil. Tujuannya adalah untuk memastikan bahwa analisis teks tidak membedakan antara huruf besar dan kecil.
- Tokenization adalah proses memecah teks menjadi unit-unit yang lebih kecil yang disebut token. Token biasanya berupa kata-kata, frasa, atau simbol.
- Stopwords adalah kata-kata umum yang sering muncul dalam teks dan biasanya diabaikan dalam analisis teks karena dianggap tidak membawa makna signifikan. Contohnya termasuk kata-kata seperti "the", "is", "in", "and"
- Lemmatization adalah proses mengubah kata-kata ke bentuk dasar atau lema mereka. Proses ini memperhitungkan konteks morfologis dari kata dan mengurangi kata-kata infleksi ke bentuk dasar mereka.
| Text | Case Folding |
|---|---|
| The quick brown foxes are jumping over the lazy dogs. | the quick brown foxes are jumping over the lazy dogs |
| Case Folding | Tokenization |
|---|---|
| the quick brown foxes are jumping over the lazy dogs | ["the", "quick", "brown", "foxes", "are", "jumping", "over", "the", "lazy", "dogs"] |
| Tokenization | Stopwords |
|---|---|
| ["the", "quick", "brown", "foxes", "are", "jumping", "over", "the", "lazy", "dogs"] | ["quick", "brown", "foxes", "jumping", "lazy", "dogs"] |
| Stopwords | Lemmatization |
|---|---|
| ["quick", "brown", "foxes", "jumping", "lazy", "dogs"] | ["quick", "brown", "fox", "jump", "lazy", "dog"] |
Feature Extraction
Ekstraksi fitur adalah proses mengidentifikasi dan memilih elemen-elemen yang relevan dari data mentah untuk digunakan dalam analisis lebih lanjut atau pembelajaran mesin. Dalam konteks teks, fitur biasanya berupa kata, frasa, atau atribut yang diidentifikasi dari teks dan digunakan sebagai input untuk model pembelajaran mesin atau teknik analisis lainnya. Beberapa teknik umum untuk ekstraksi fitur dalam pemrosesan teks termasuk:
- Bag-of-Words (BoW): Mengubah teks menjadi representasi vektor berdasarkan frekuensi kata.
- TF-IDF: Mengukur kepentingan suatu kata dalam sebuah dokumen relatif terhadap seluruh korpus.
- Word Embeddings: Mengubah kata menjadi representasi vektor berdimensi tetap yang menangkap makna semantik (misalnya, Word2Vec, GloVe).
- N-grams: Mengambil urutan dari n kata sebagai fitur untuk mempertahankan konteks lokal dalam teks.
- Part-of-Speech Tagging: Menggunakan kategori gramatikal (misalnya, kata benda, kata kerja) sebagai fitur.
- Named Entity Recognition (NER): Mengidentifikasi dan mengekstraksi entitas bernama (misalnya, orang, lokasi, organisasi).
Misalkan kita memiliki beberapa kalimat lain dalam korpus untuk mendapatkan nilai TF-IDF yang lebih bermakna. Berikut datanya:
- "quick brown fox jump lazy dog"
- "lazy dog sleep all day"
- "quick dog run fast"
- "brown fox and lazy dog are friends"
Langkah-Langkah Ekstraksi Fitur TF-IDF :
- Term Frequency (TF) mengukur seberapa sering suatu kata muncul dalam sebuah dokumen. Rumus TF untuk suatu kata 𝑡 dalam dokumen 𝑑 d adalah:
- Inverse Document Frequency (IDF) mengukur kepentingan suatu kata. Rumus IDF untuk suatu kata 𝑡 adalah:
- TF-IDF adalah perkalian dari TF dan IDF:
\( \text{TF}(t, d) = \frac{\text{Jumlah kemunculan t dalam d}}{\text{Total kata dalam d } } \)
\( \text{IDF}(t) = \log \left( \frac{\text{Jumlah dokumen dalam korpus}}{\text{Jumlah dokumen yang mengandung } t} \right) \)
\( \text{TF-IDF}(t, d) = \text{TF}(t, d) \times \text{IDF}(t) \)
Hitung TF-IDF untuk Kalimat "quick brown fox jump lazy dog"
- Kalimat "quick brown fox jump lazy dog" memiliki 6 kata unik: "quick", "brown", "fox", "jump", "lazy", "dog".
- TF("quick", d1) = 1/6
- TF("brown", d1) = 1/6
- TF("fox", d1) = 1/6
- TF("jump", d1) = 1/6
- TF("lazy", d1) = 1/6
- TF("dog", d1) = 1/6
- Hitung IDF. Untuk masing-masing kata:
- IDF("quick") = log(4/2) = log(2) ≈ 0.693
- IDF("brown") = log(4/2) = log(2) ≈ 0.693
- IDF("fox") = log(4/2) = log(2) ≈ 0.693
- IDF("jump") = log(4/1) = log(4) ≈ 1.386
- IDF("lazy") = log(4/3) = log(1.333) ≈ 0.287
- IDF("dog") = log(4/4) = log(1) = 0
- Hitung TF-IDF
- TF-IDF("quick", d1) = TF("quick", d1) * IDF("quick") = (1/6) * 0.693 ≈ 0.116
- TF-IDF("brown", d1) = TF("brown", d1) * IDF("brown") = (1/6) * 0.693 ≈ 0.116
- TF-IDF("fox", d1) = TF("fox", d1) * IDF("fox") = (1/6) * 0.693 ≈ 0.116
- TF-IDF("jump", d1) = TF("jump", d1) * IDF("jump") = (1/6) * 1.386 ≈ 0.231
- TF-IDF("lazy", d1) = TF("lazy", d1) * IDF("lazy") = (1/6) * 0.287 ≈ 0.048
- TF-IDF("dog", d1) = TF("dog", d1) * IDF("dog") = (1/6) * 0 = 0
Hasil Akhir TF-IDF untuk kalimat "quick brown fox jump lazy dog":
- TF-IDF("quick") ≈ 0.116
- TF-IDF("brown") ≈ 0.116
- TF-IDF("fox") ≈ 0.116
- TF-IDF("jump") ≈ 0.231
- TF-IDF("lazy") ≈ 0.048
- TF-IDF("dog") = 0
Setelah melakukan proses ekstraksi fitur, langkah-langkah berikutnya dalam analisis teks atau pemrosesan pembelajaran mesin melibatkan berbagai tahapan yang bertujuan untuk membangun, menguji, dan menerapkan model yang diinginkan.
- Pembagian Data
- Training dan Testing: Data biasanya dibagi menjadi set pelatihan (training set) dan set pengujian (testing set). Set pelatihan digunakan untuk melatih model, sementara set pengujian digunakan untuk mengevaluasi kinerja model.
- Pemilihan Model
- Memilih Algoritma: Memilih algoritma pembelajaran mesin yang sesuai untuk tugas yang dihadapi, seperti klasifikasi, regresi, clustering, dll. Contoh algoritma termasuk Decision Trees, Random Forest, Support Vector Machines (SVM), Neural Networks, dll.
- Pelatihan Model
- Training: Melatih model menggunakan set pelatihan. Proses ini melibatkan penyesuaian parameter model untuk meminimalkan kesalahan atau memaksimalkan kinerja pada data pelatihan.
- Evaluasi Model
- Evaluasi: Menggunakan set pengujian untuk mengevaluasi kinerja model klasifikasi. Metrik evaluasi umum meliputi akurasi, presisi, recall, F1-score, mean squared error, dll.
Confusion matrix adalah alat yang digunakan untuk mengevaluasi kinerja model. Ini memberikan gambaran yang jelas tentang seberapa baik model klasifikasi Anda bekerja dengan menampilkan jumlah prediksi yang benar dan salah untuk masing-masing kelas. Confusion matrix berbentuk tabel yang menampilkan empat komponen utama untuk model biner (dua kelas), namun konsep ini dapat diperluas untuk klasifikasi multikelas. Berikut adalah komponen untuk model biner:
- True Positive (TP): Jumlah sampel yang benar-benar positif dan diprediksi positif.
- True Negative (TN): Jumlah sampel yang benar-benar negatif dan diprediksi negatif.
- False Positive (FP): Jumlah sampel yang sebenarnya negatif tetapi diprediksi positif (False Alarm).
- False Negative (FN): Jumlah sampel yang sebenarnya positif tetapi diprediksi negatif (Missed Detection).
Predicted Positive Predicted Negative Actual Positive True Positive (TP) False Negative (FN) Actual Negative False Positive (FP) True Negative (TN)
Rumus :
\( \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} \)\( \text{Precision} = \frac{TP}{TP + FP} \)\( \text{Recall} = \frac{TP}{TP + FN} \)\( \text{F1-Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} \)- K-Fold Cross Validation: Teknik validasi silang untuk memastikan model tidak overfitting dengan membagi data menjadi K bagian dan melakukan pelatihan serta pengujian K kali.
- Hyperparameter Tuning
- Grid Search/Random Search: Mencari kombinasi terbaik dari hyperparameter untuk meningkatkan kinerja model.
- Bayesian Optimization: Teknik yang lebih canggih untuk mencari hyperparameter optimal.
- Penanganan Overfitting dan Underfitting
- Regularization: Menambahkan penalti pada parameter model untuk mengurangi kompleksitas model.
- Pruning: Mengurangi ukuran atau kompleksitas model, terutama pada pohon keputusan.
- Implementasi dan Deployment
- Deployment: Menerapkan model yang telah dilatih ke dalam lingkungan produksi untuk digunakan pada data baru.
- Monitoring: Memantau kinerja model secara berkelanjutan untuk memastikan model tetap berfungsi dengan baik dan melakukan pembaruan jika diperlukan.
- Peningkatan Model
- Feedback Loop: Menggunakan data baru dan umpan balik untuk terus meningkatkan model.
- Feature Engineering: Mengembangkan fitur-fitur baru atau memperbaiki fitur yang ada berdasarkan wawasan yang diperoleh dari analisis model dan data.
Dengan mengikuti langkah-langkah ini, kita dapat memastikan bahwa model yang dibangun dapat memberikan hasil yang andal dan dapat diterapkan secara efektif dalam situasi nyata.